Since Neo4j released vector search indexes as a public beta in the 5.11 version, we have started to think about how it could enhance the already existing Graphileon ChatGPT integrations that we’ve built for our customers. We quickly found out that adding embeddings to the nodes of a fully controlled knowledge graph opens a lot of possibilities, including Retrieval Augmented Generation (RAG). In such a scenario, we retrieve relevant context (a set of chunks of text) using a vector search and add it to the prompt that is sent to ChatGPT, while telling it to only use the context that we provide to generate an answer.
In this blog, we go through the following steps:
- Decide on the data model and set up a vector search index in Neo4j.
- Create (:Page) nodes.
- Create chunks of text in the (:Chunk) nodes, and create embeddings using the OpenAI endpoint.
- Run the vector search in the Graphileon user interface.
- Set up a public API endpoint in Graphileon.
- The fun part! Have a conversation with ChatGPT.
- Conclusion.
At the end of this post, you will find downloadable files with, among others, the Graphileon configuration in JSON format,
Decide on the data model and set up a vector search index in Neo4j
We will use a simple data model, consisting of :Page and :Chunk nodes, which are connected by :CHUNK relationships.
(:Page {source:string, date:string})-[:CHUNK {chunkIndex: integer}]->(:Chunk {content:string, embedding:arrayOfFloat})
Since we plan to use the OpenAI embeddings we chose a vector length of 1536 for the embeddings that we will be adding to the (:Chunk) nodes.
The following command creates the vector search index:
CALL db.index.vector.createNodeIndex('chunk-embeddings', 'Chunk', 'embedding', 1536, 'cosine')
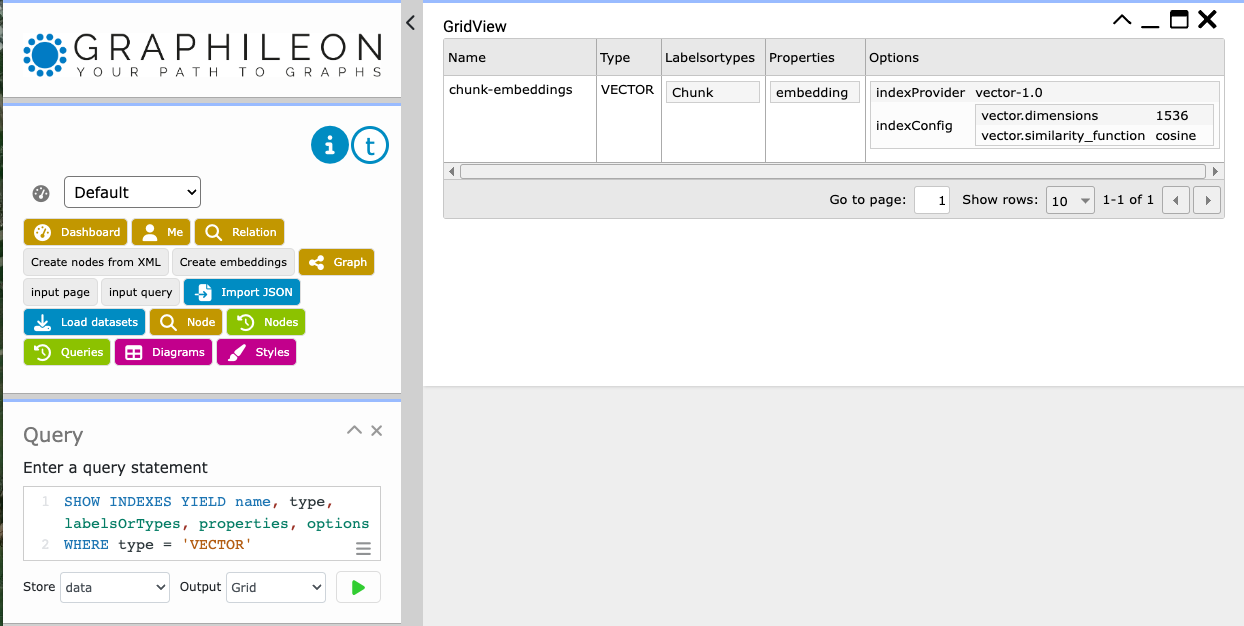
We test the existence of the index:
SHOW INDEXES YIELD name, type, labelsOrTypes, properties, options WHERE type = 'VECTOR'
When we do this in the Graphileon UI, the result is sent to a GridView:
Create (:Page) nodes
We exported the list from URLs from our CMS and online documentation to an XML file.

First, we created a constraint on the source property, then we create the :Page nodes
CALL apoc.load.xml("graphileon_urls.xml")
YIELD value
UNWIND value._children AS page
WITH HEAD([ i IN page._children WHERE i._type = 'loc'])._text AS url,
left(HEAD([ i IN page._children WHERE i._type = 'lastmod'])._text,10) AS date
MERGE (p:Page {source: url})
SET p.date = date
Create chunks of text in the (:Chunk) nodes, and create embeddings using the OpenAI endpoint.
After having cleaned up any existing :Chunk nodes, we create a collection of :Page sources and feed this to an Iterate function
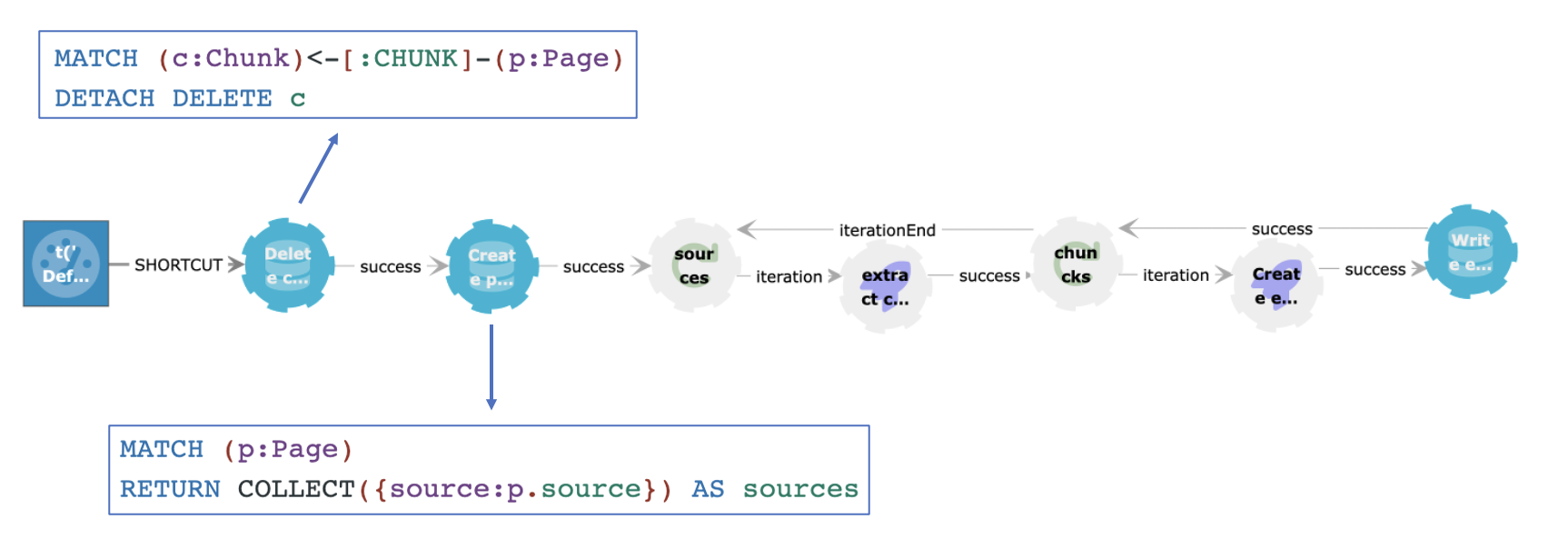
On the trigger that is fired by the query after successful execution, the result of the query is mapped to the #data property from the Iterate function. On each iteration, the content from a page is processed.
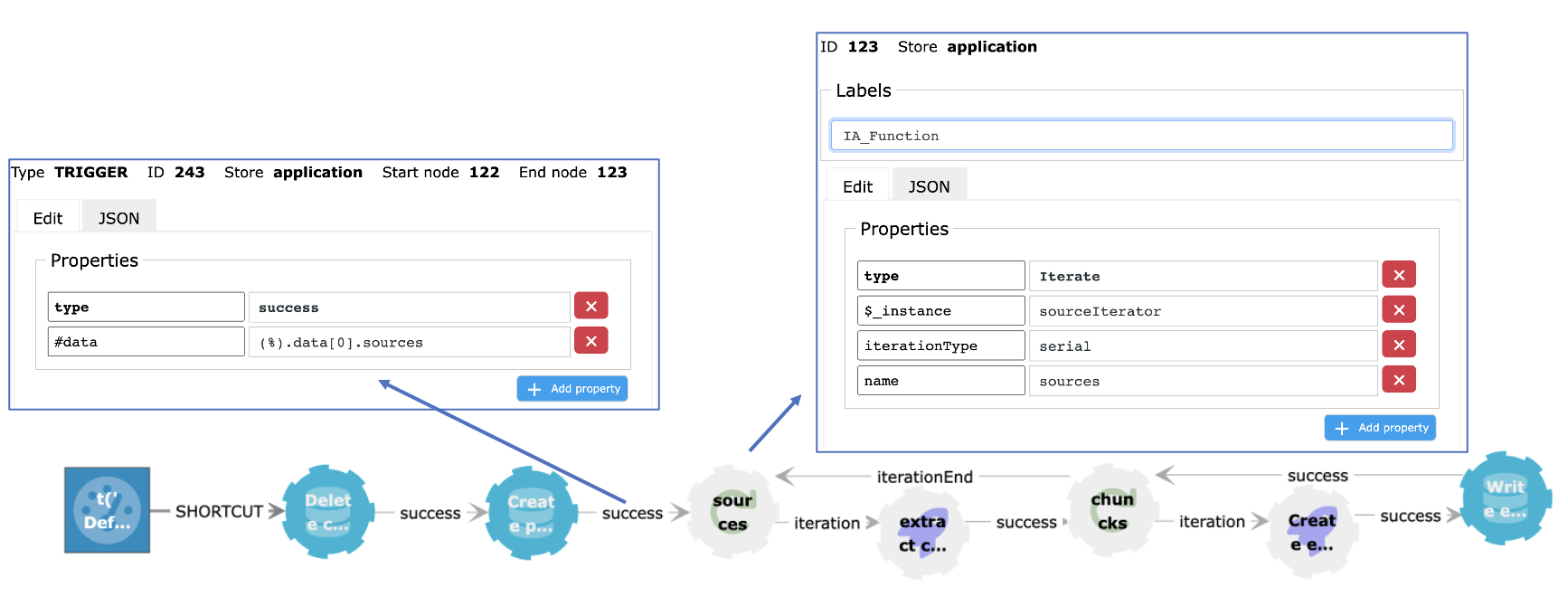
To extract the content from the URL that is stored in the source, and cut it into chunks of 512 characters with an overlap of 20, we make a request to a custom endpoint on each iteration. This endpoint returns an array of chunks which is sent to the second Iterator.
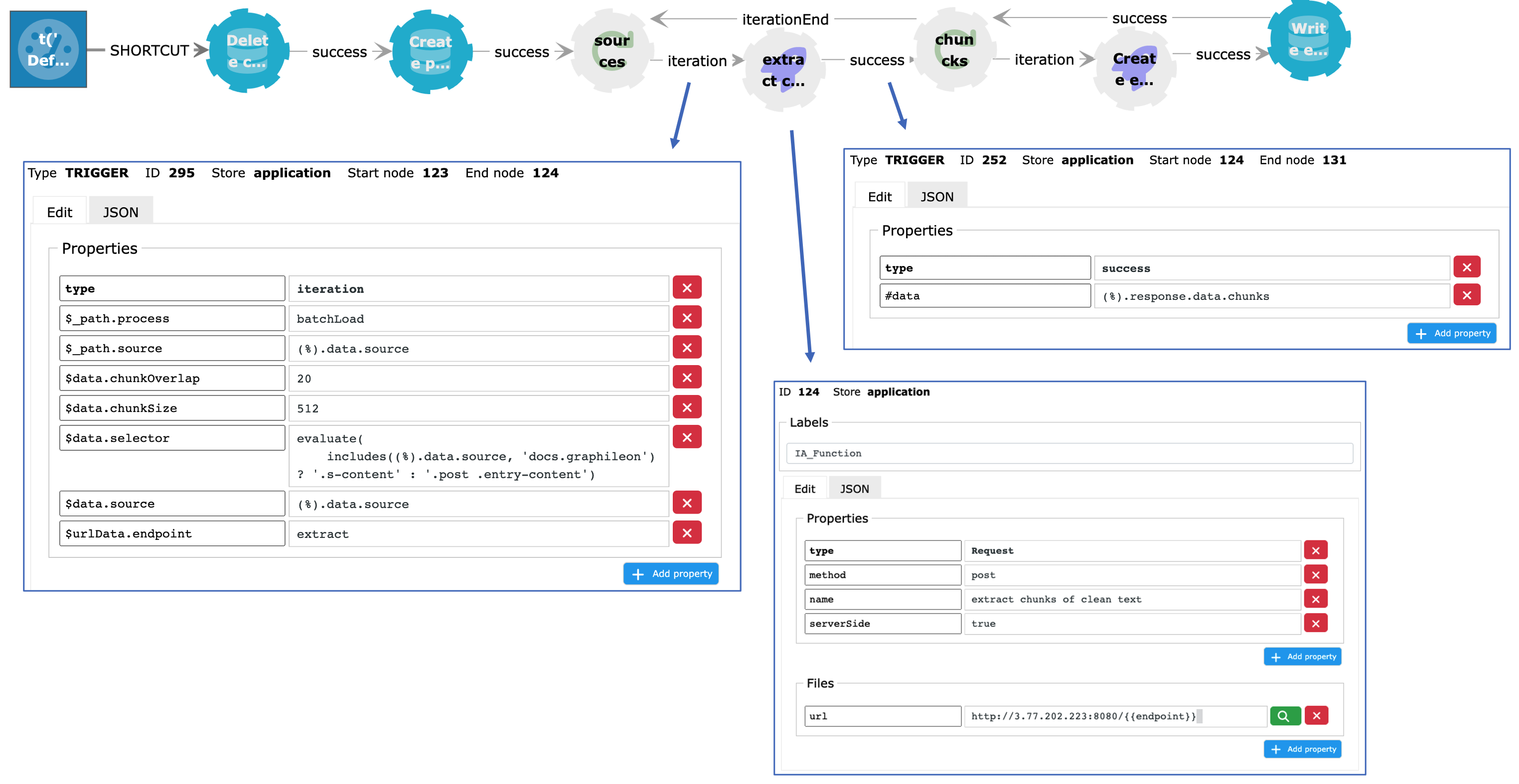
You can find the code of the services running at the /split and /extract endpoints here.
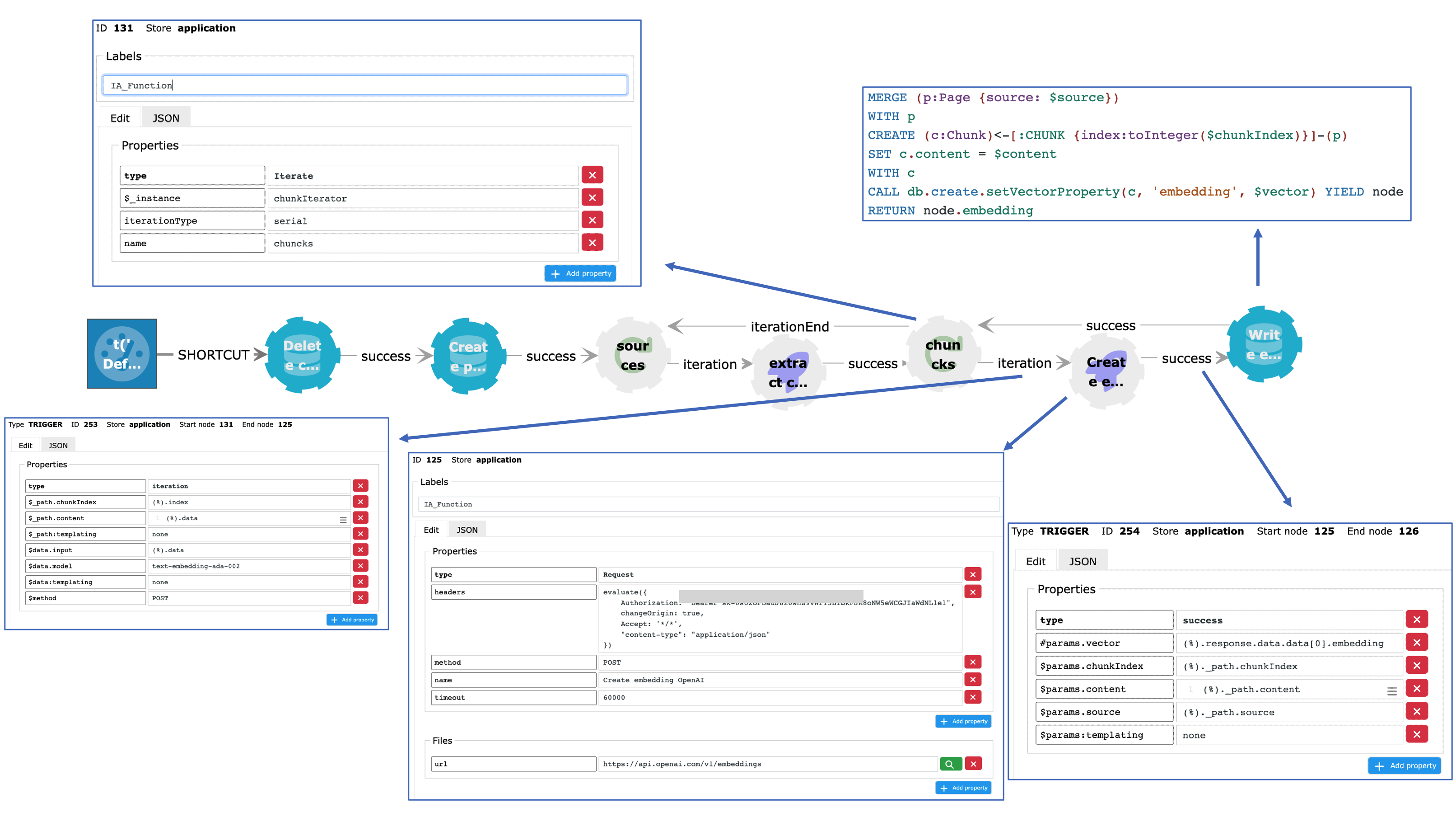
When looping through the array of chunks, we use the OpenAI embeddings endpoint and the text-embedding-ada-002 model. This model returns a vector of length 1536. For each chunk, a :Chunk node is created in the Neo4j store and connected to the corresponding :Page node. The vector is added to the :Chunk node and will be automatically indexed.
Run the vector search in the Graphileon user interface
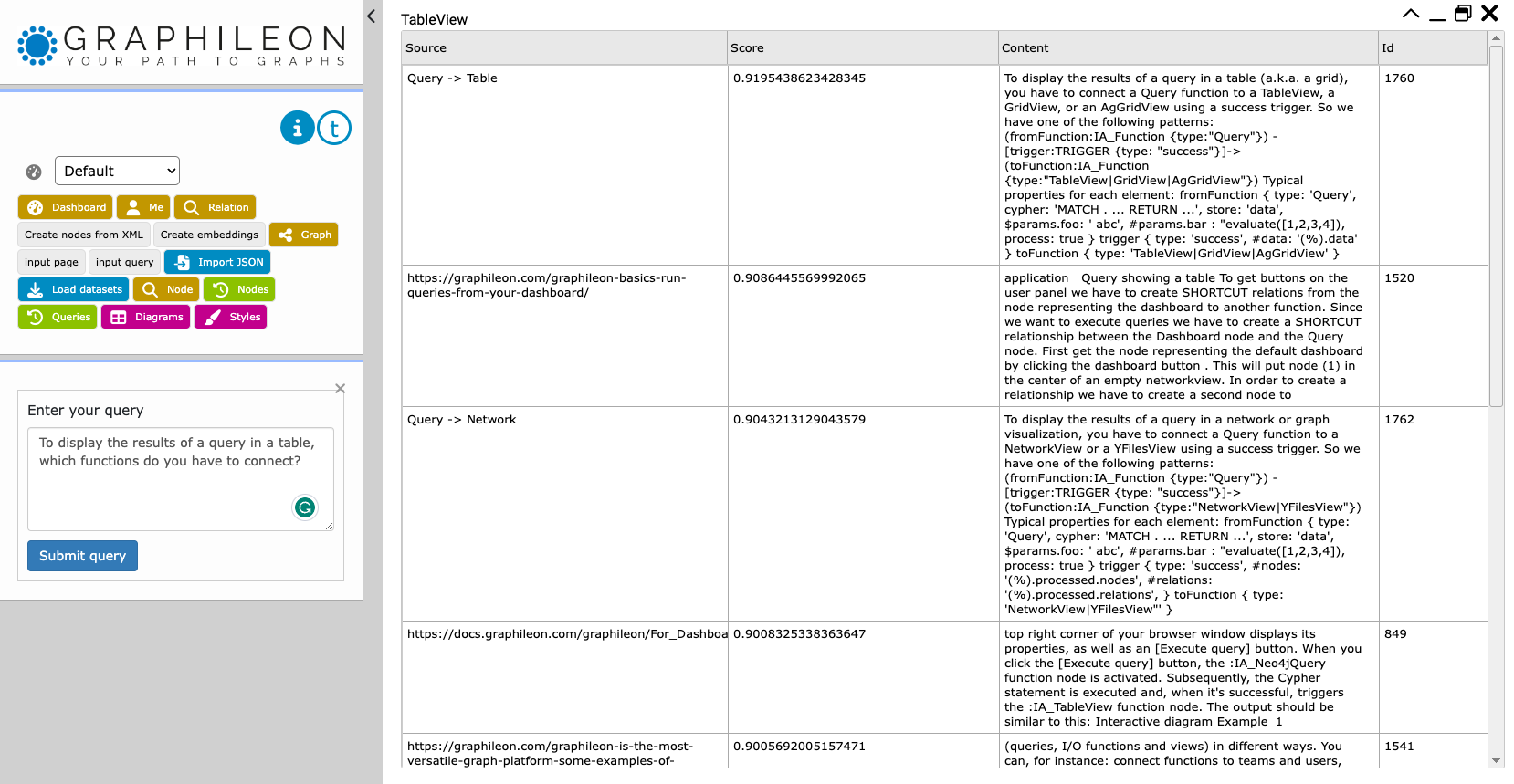
To test whether everything works fine, we created a small configuration in the Graphileon UI. It consists of an InputView in which the user enters a query, a Request to the OpenAI embeddings endpoint (that returns the embedding of the query), a Query with a statement to retrieve the nearest :Chunk nodes, and a TableView to display the results.

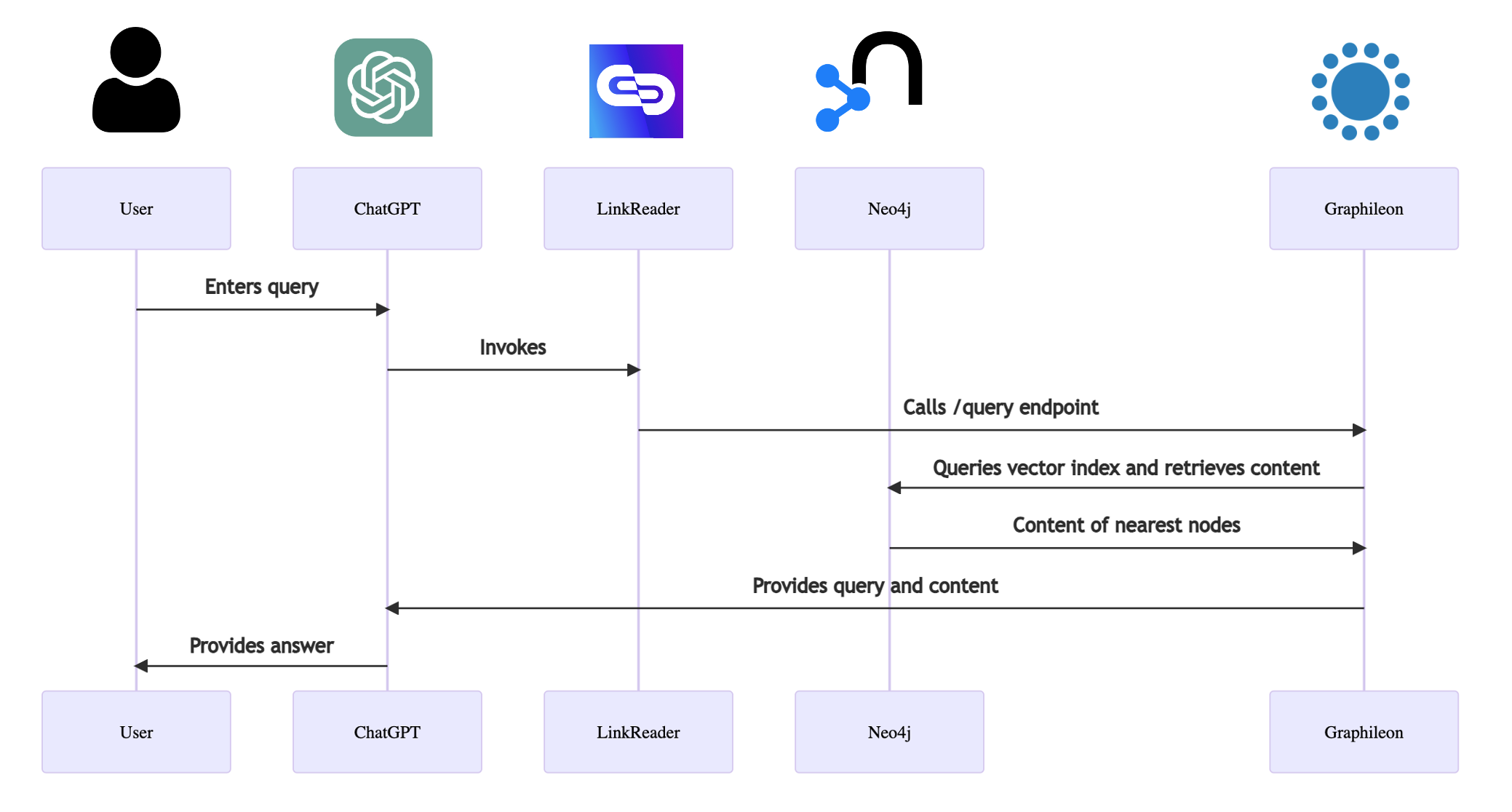
If we want to use the nearest chunks as our data source for a meaningful conversation in ChatGPT, we have to make sure that ChatGPT can access our vector search. This is our next step.
Set up a public API endpoint in Graphileon
The public API endpoint that we will be setting up takes the query as a parameter q, and it will return the content of the 10 nearest nodes (based on cosine similarity). The Graphileon configuration consists of an API function (the endpoint), a Request (to create an embedding of the query and a Query that returns the contents of the 10 nearest :Chunk nodes. Contrary to the test setup above, the result is not sent to a TableView, but as a response to the API function, which will forward it to the caller.
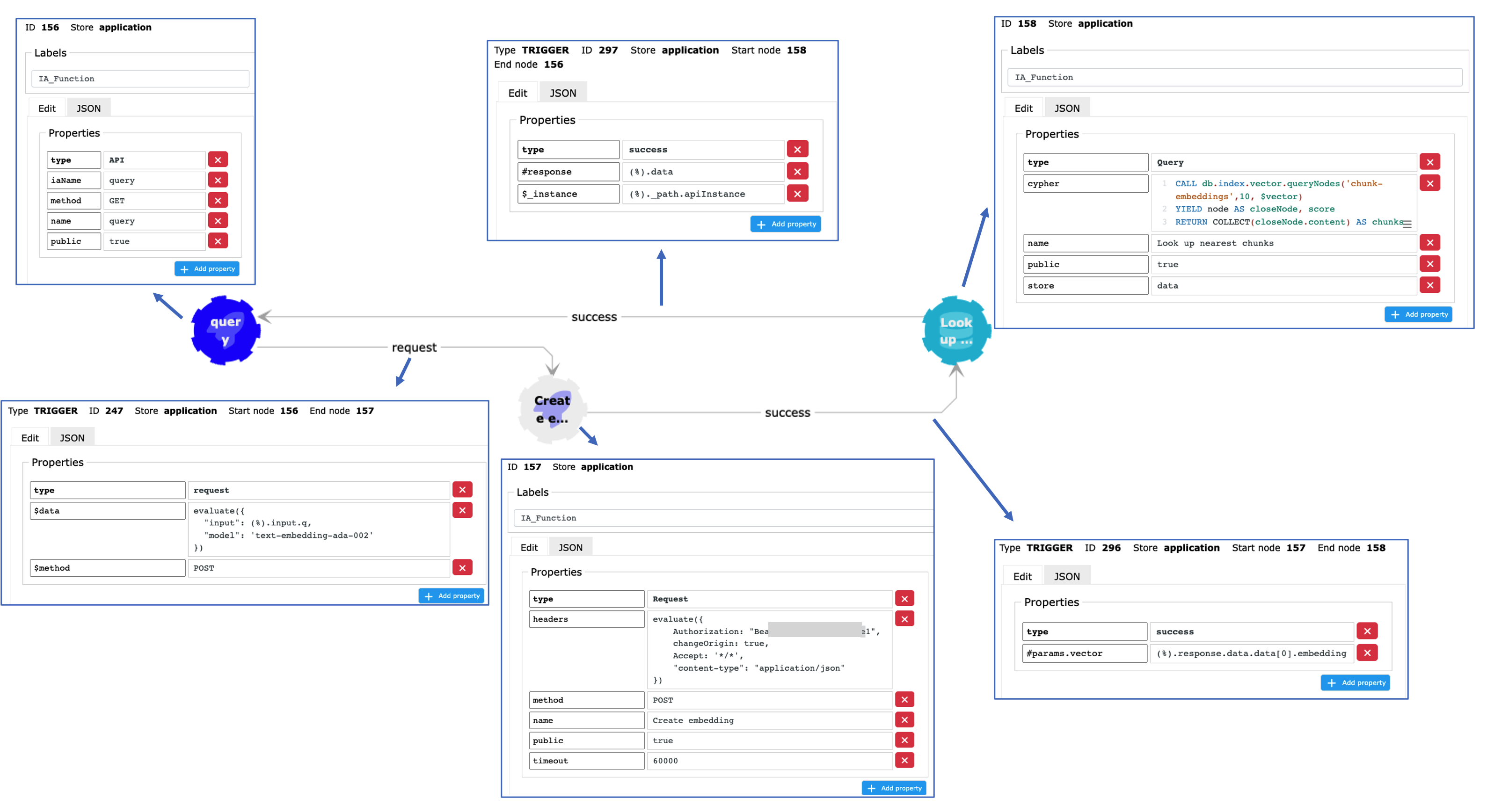
The API function has a property iaName with value “query“, which determines the address of the endpoint. So, in our case the GET request looks like this:
https://mycloudinstance.graphileon.app/api/app/query?q=myQuery
The fun part! Have a conversation with ChatGPT
As we will make calls to endpoints, we are using the Link Reader plugin in combination with GPT-4.
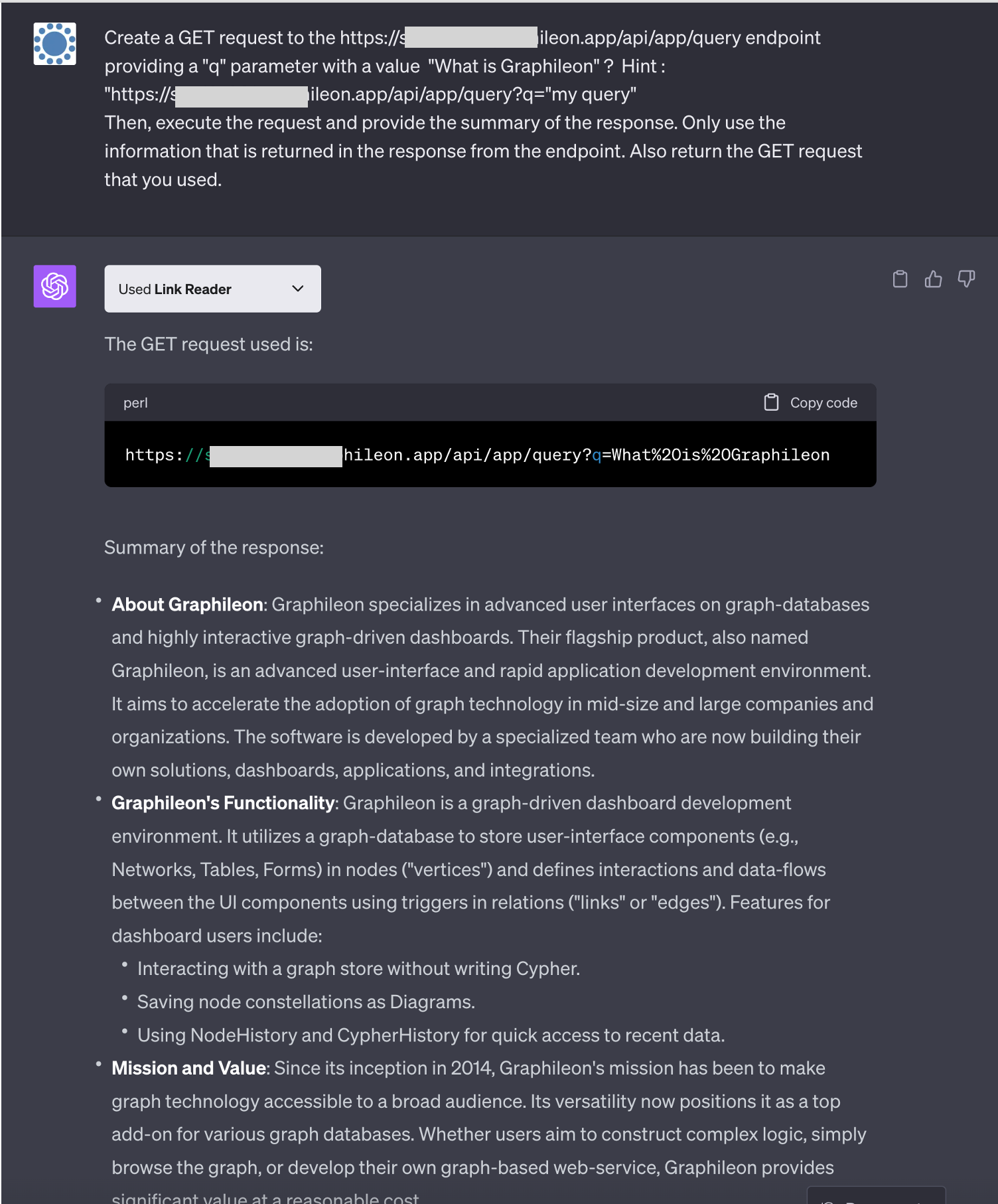
This is pretty OK, so we asked ChatGPT to dive into our documentation:
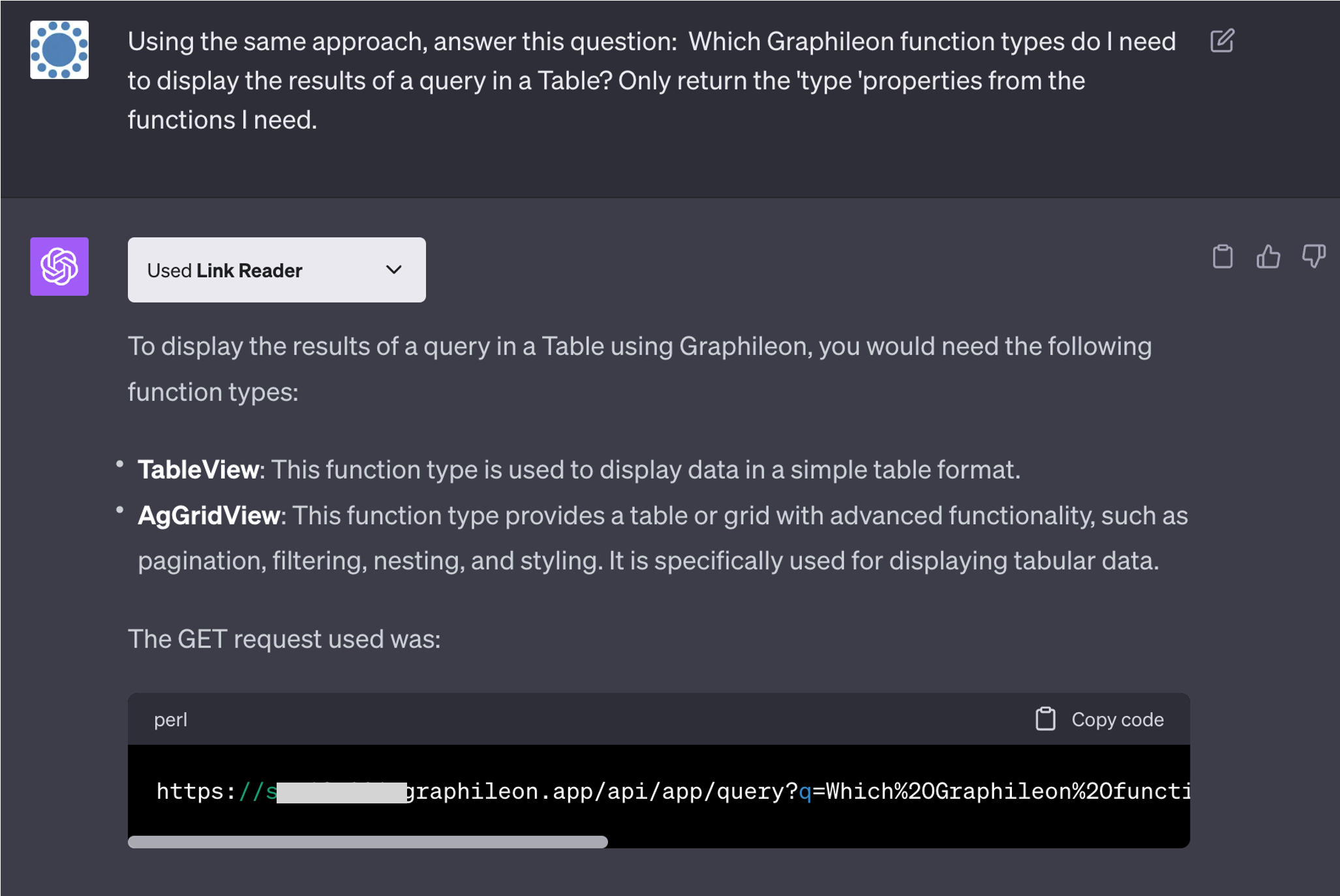
It missed the Query function, so we told ChatGPT to try again and provide some additional information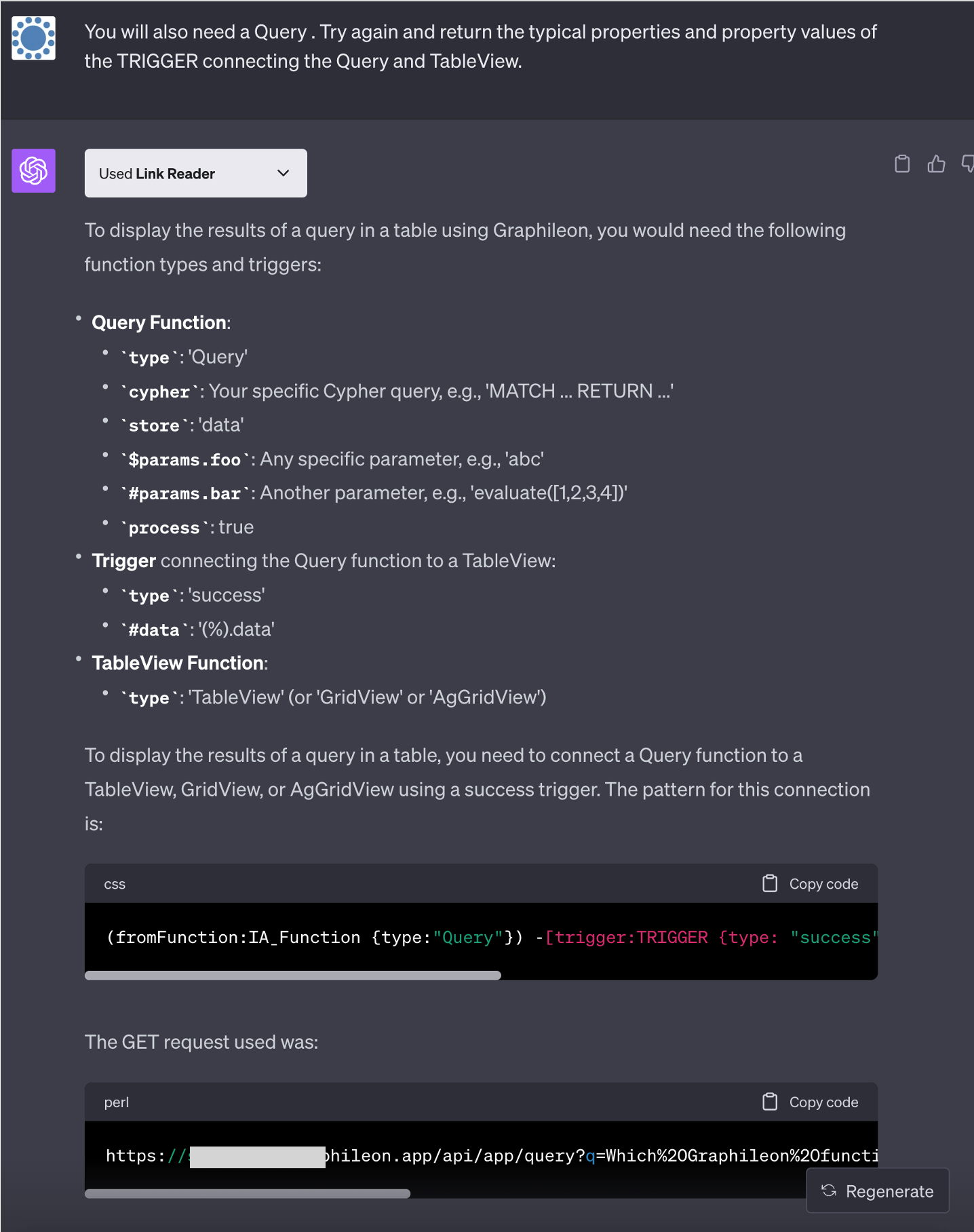
Which is pretty awesome.
To further test whether ChatGPT really limits its response to what it can find in the context that the endpoint returns, and to confirm that we can handle a dynamic dataset, we added another page of content to the knowledge base:
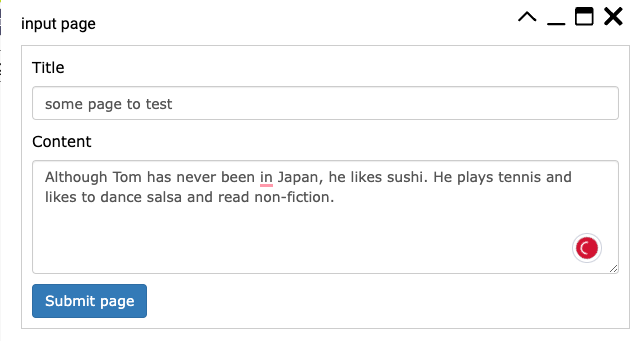
After the embedding was created, we continued our conversation with ChatGPT:

Conclusion
With under 20 Graphileon functions, we were able to set up a production-ready RAG configuration that returns relevant results from a dynamic dataset, leveraging the latest innovations in the field of graph databases, vector search, and generative AI. It’s a very cost-effective and efficient approach in situations where resources for finetuning LLMs are lacking. Graphileon’s powerful standard functions and lowcode, graph based function-trigger infrastructure not only allowed us to build the integration with Neo4j and ChatGPT in a couple of hours but also ensured the integration with a far wider range of applications.
Downloads
- Graphileon configuration in JSON format
- Custom endpoint setup (javascript)
- Links to Graphileon pages in XML

 Cloud
Cloud